




Replication
made simple with Pipelyt
Chose a Connector, source and destination and you are off to the races!










Vectors Where You Need Them
Enterprise scale throughput, one click setup, and live monitoring everything you need to keep vector data always in sync.
Experience The Future Of Vector Replication
The fastest and easiest way to replicate Pinecone, Weaviate, Qdrant, Milvus & more.
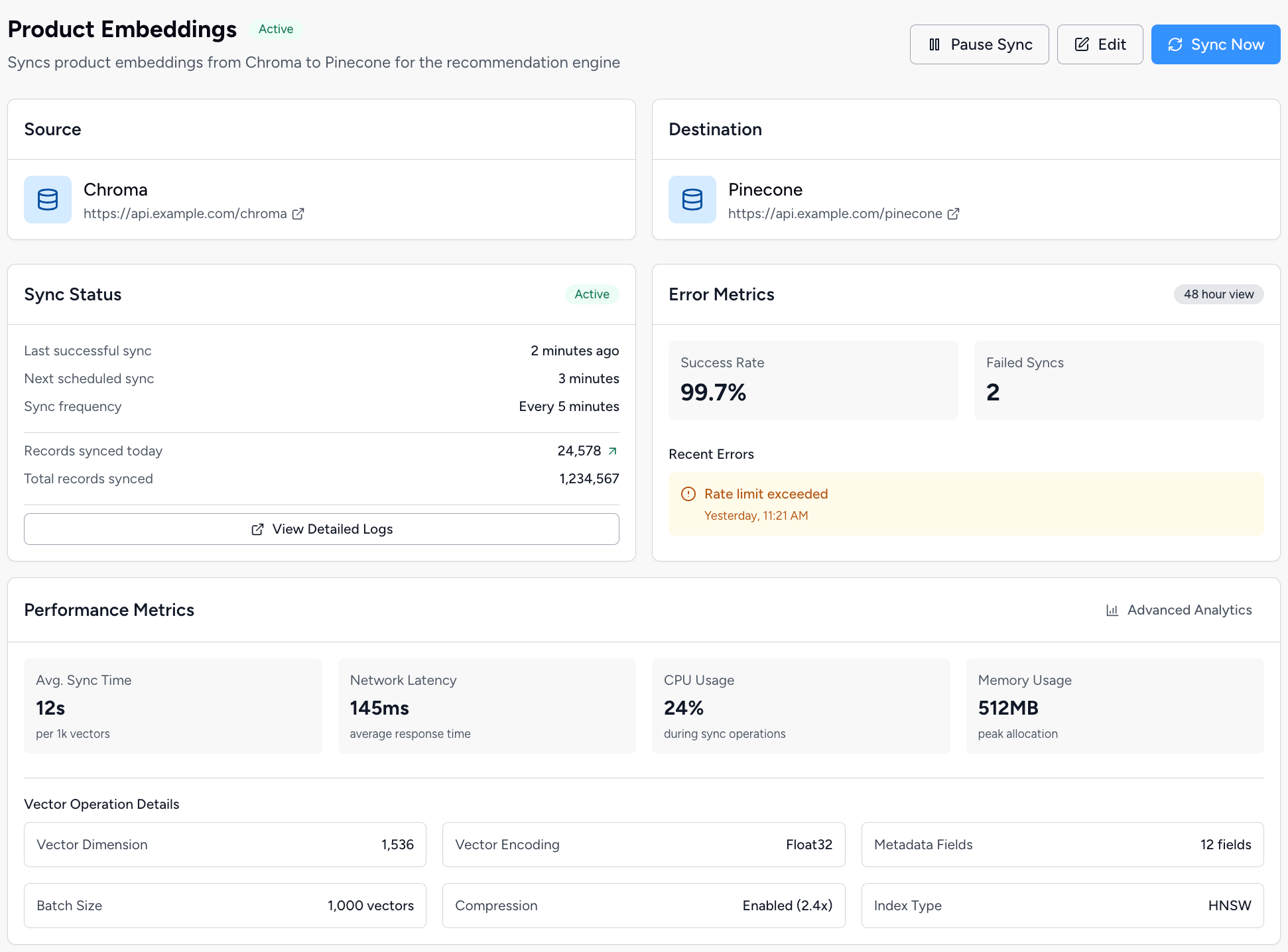
Pipeline Health
Latency, throughput & error logs live, in one place.
Connect & Replicate
Pick a source, pick a destination, hit Start Sync. We handle the rest.
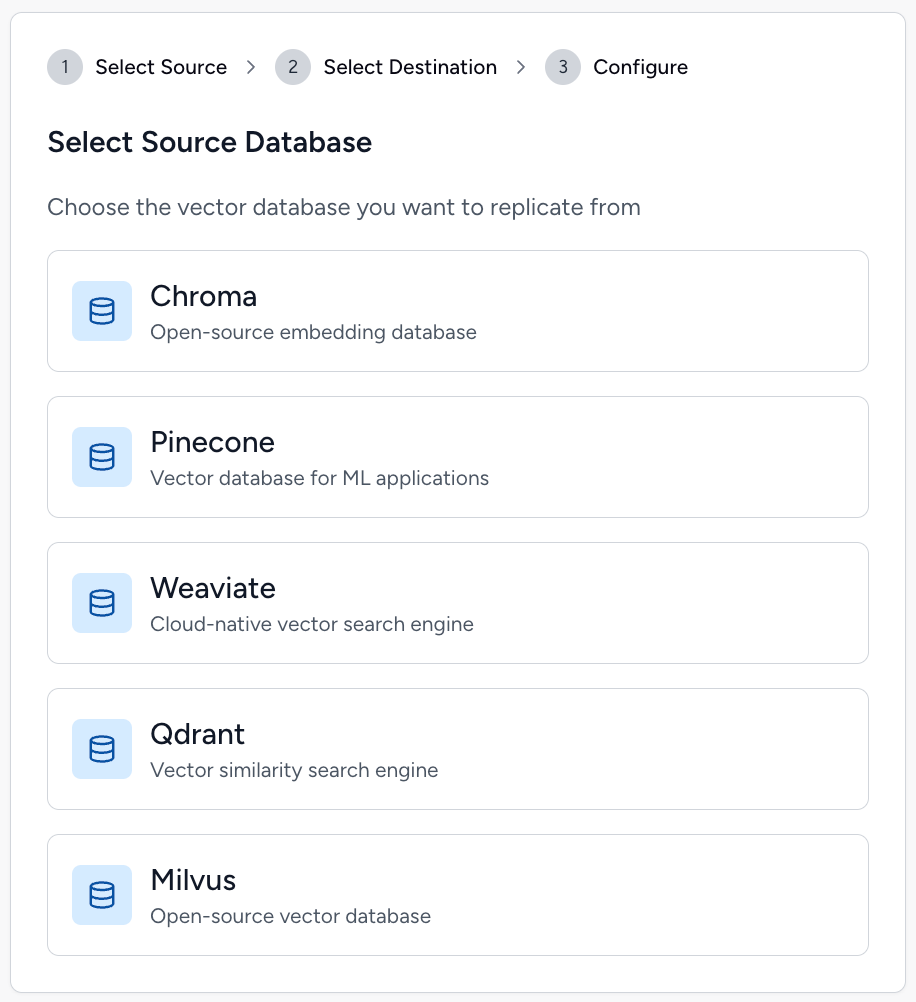
Create Connection
Select your vector DBs configure once, replicate forever.
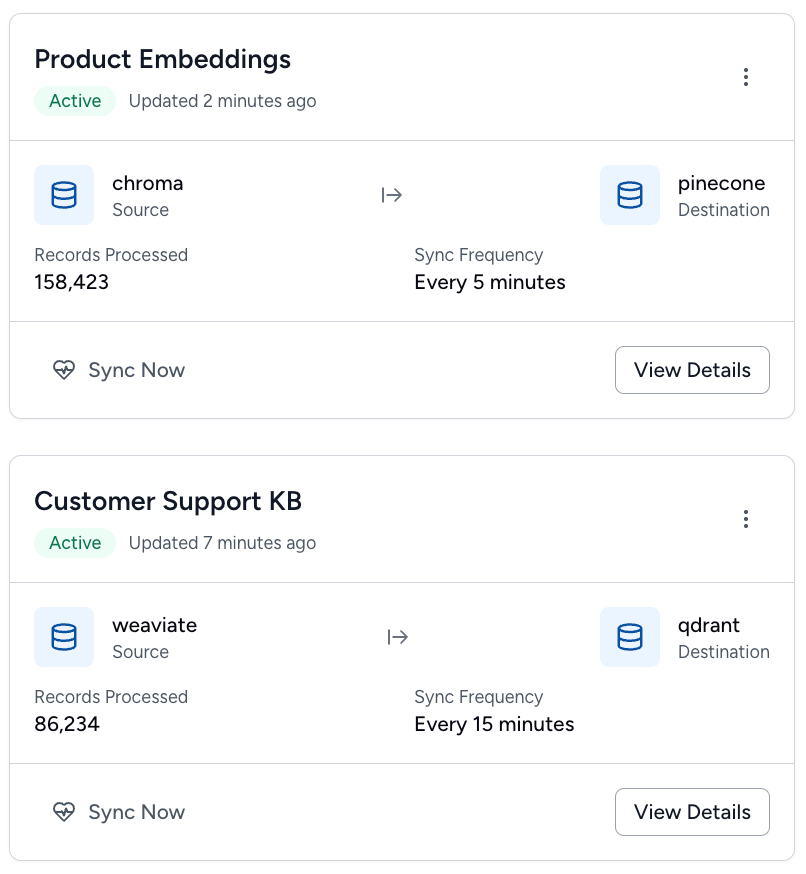
Stay in the Loop
24 / 7 visibility and notifications for each embedding stream.
Empowering Vector Data Mobility With Pipelyt
With these features, Pipelyt enables effortless, reliable, and flexible vector database replication empowering teams to scale, migrate, and modernize their AI infrastructure without friction.

Multi-Provider Connectors
Easily connect to leading vector databases like Pinecone, Weaviate, Qdrant, Milvus, and more.

Schema + Metadata Mapping
Intelligently maps and transfers both embeddings and associated metadata no manual work required.

Real-Time or Scheduled Sync
Support for low latency syncs or scheduled batch jobs based on your replication strategy.

Index Format Conversion
Convert index types between providers to match performance and cost requirements.

Monitoring & Logging
Track every replication job with detailed logs, status tracking, and alerts.
Why Teams Choose Pipelyt
Vector databases are creating a new vendor lock-in issues. Teams waste months building one off migration scripts

Disaster Recovery
Multi-cloud DR without vendor lock-in.

Testing & Development
Replicate production data for testing.

Cost Optimization
Migrate to cheaper/faster stores.

AI/RAG Applications
Critical for production AI infrastructure.
Frequently Asked Questions
The data replication tool that understands embeddings, dimensions, and the unique needs of vector databases.
How is Pipelyt different from existing data replication tools like Fivetran or Airbyte?
Traditional data replication tools treat vectors as generic binary data. They can move bytes, but they can't preserve the semantic relationships that make embeddings work. Pipelyt understands vector data—we validate that cosine similarity stays consistent, handle dimension mismatches, and ensure your search results remain identical across replicas. Plus, we support true bi-directional sync between any vector databases, not just one-way data loading.
What vector databases does Pipelyt support?
We support all major vector databases including Pinecone, Chroma, Weaviate, Qdrant, Milvus, Zilliz Cloud, pgvector, and more to come. Our architecture is designed to add new connectors rapidly, if you need a specific database, we can usually add support within weeks.
How do you handle different embedding dimensions and value ranges between databases?
This is where our vector-specific intelligence shines. We automatically detect dimension mismatches (e.g., 384D → 1536D) and apply appropriate normalization techniques like padding, truncation, or linear transformation. We also handle value range conversion (0-1 → -1 to 1) and validate that distance metrics remain consistent post-transformation.
How fast is the replication? What's the latency?
Sub-second latency for most operations. Simple vector updates typically replicate within 100-500ms. Large batch operations or full index rebuilds may take longer depending on size, but we provide real-time progress monitoring and can parallelize transfers for maximum speed.
Can I replicate to multiple destinations simultaneously?
Absolutely. One of our key advantages is one-to-many replication. You can sync a single source to multiple vector databases simultaneously—perfect for multi-cloud DR, A/B testing, or maintaining dev/staging environments.
How do you ensure data consistency across replicas?
We implement exactly-once delivery guarantees and continuous semantic validation. Every replicated vector is verified to ensure search results match the source. We also provide conflict resolution for multi-master scenarios and real-time monitoring to detect any drift.
Do you support real-time replication or just batch migrations?
Both! We excel at real-time continuous replication (CDC) for keeping systems in sync, but we also support one-time migrations when you're switching vendors. You can even start with a migration and then switch to ongoing replication.
How do you handle metadata and custom fields?
We automatically map metadata schemas between different vector databases. Custom fields, namespaces, collections, and indexes are preserved wherever possible. When exact mapping isn't possible, we provide configurable transformation rules.
How does Pipelyt compare to building an in-house solution?
Building production grade vector replication requires expertise in distributed systems, vector mathematics, database internals, and ongoing maintenance. Our customers typically save 6-18 months of engineering time and can focus on their core AI features instead of data plumbing.
Start Your Vector Replication Journey Today
Join teams modernizing their AI infrastructure without vendor lock-in or manual data transfers.

